
Dans un article précédent, nous avons abordé le concept d’Intelligent process automation (IPA). Définie comme la combinaison de l’automatisation robotisée des processus (RPA) et de l’intelligence artificielle (IA), l’automatisation intelligente peut traiter des données non structurées et semi-structurées pour automatiser des processus métier complexes de bout en bout, et apprendre à améliorer ses performances à mesure que des données supplémentaires lui sont fournies.
Le terme d’intelligence artificielle recouvre de très nombreuses technologies, qui incluent entre autres l’apprentissage automatique, l’apprentissage profond, le traitement du langage naturel et les réseaux neuronaux. Toute discussion sur l’automatisation intelligente doit également tenir compte d’une technologie d’IA de plus en plus importante : la vision par ordinateur.
Vision par ordinateur : notions de base
La vision par ordinateur est une technologie émergente qui fait encore l’objet de recherches. Il serait donc plus approprié de la qualifier de domaine en développement. Elle permet aux ordinateurs de « voir » et de comprendre le contenu d’images numériques telles que des photographies, des PDF, des diagrammes, des dessins, des vidéos, etc.
Pourquoi est-ce si important pour la transformation digitale ? En raison de toutes les images (fixes ou animées) qui existent sous forme numérique. Le texte est relativement facile à comprendre et à manipuler pour des algorithmes. Les images sont autrement plus complexes.
Pour pouvoir comprendre le contenu des images, nous dépendons des descriptions fournies par les humains. Ces descriptions sont appelées métadonnées, c’est-à-dire des données sur les données. Mais des métadonnées telles que « facture » ou « permis de conduire » ne suffisent pas à restituer toute l’information contenue dans ces images. Pour extraire cette information, nous avons besoin de programmes capables de voir les images comme le font les humains et de comprendre leur contenu.
Bien qu’il s’agisse d’un défi relativement trivial pour les humains, il s’est avéré étonnamment difficile pour les machines. Un être humain peut regarder un document et dire : « Il s’agit d’une facture », même si elle est formatée différemment des autres factures, si elle comporte un logo différent, des couleurs ou des polices différentes. Les ordinateurs doivent être formés à cette tâche. Pour ce faire, on utilise l’apprentissage automatique, c’est-à-dire que l’on nourrit le système de nombreuses images et on l’amène à associer des images similaires les unes aux autres.
La vision par ordinateur est une technologie de plus en plus populaire à intégrer dans les projets d’automatisation et de transformation digitale. La taille du marché mondial de la vision par ordinateur était estimée à 10,56 milliards de dollars en 2019 et devrait atteindre 11,44 milliards de dollars en 2020, selon Grand View Research.
Vision par ordinateur vs. technologie OCR
Nombreux sont ceux qui confondent la vision par ordinateur, encore émergente, avec la technologie plus ancienne et relativement mature de reconnaissance optique de caractères (OCR). L’OCR est un sous-ensemble de la vision par ordinateur qui effectue uniquement la reconnaissance de texte. Elle extrait et numérise les textes imprimés, dactylographiés et certains textes manuscrits. Elle convertit les caractères analogiques en caractères numériques.
D’une certaine manière, l’OCR a été la première incursion (limitée) dans la vision par ordinateur. Aujourd’hui, cependant, la vision par ordinateur fait beaucoup plus que simplement extraire du texte. Elle utilise l’apprentissage automatique et l’apprentissage profond pour examiner une image du même point de vue qu’un être humain, c’est-à-dire pour comprendre tout le contenu qu’elle contient. Par exemple, si on lui fournit la photographie d’un panneau de signalisation, l’OCR peut extraire les lettres S-T-O-P. En revanche, les applications de vision par ordinateur peuvent analyser la forme du panneau, sa couleur et sa position par rapport à d’autres objets. Cela renforce considérablement la fiabilité des résultats, tout en agrandissant le champ des possibles.
Exemples d’utilisation de la vision par ordinateur pour l’automatisation intelligente
Voici quelques façons dont la vision par ordinateur est déjà utilisée pour alimenter des applications d’automatisation intelligente :
- Traitement des factures : Les factures se présentent sous toutes les formes, par toutes sortes de canaux, et se manifestent par toutes sortes de données non structurées sous forme d’images (courriel, télécopie, PDF). Elles peuvent même être fournies sous forme manuscrite et remises en main propre. L’automatisation intelligente qui utilise la vision par ordinateur peut reconnaître tout le contenu important (nom du fournisseur, devise, date d’échéance, montant, références produits, etc.), l’extraire et le traiter pour le paiement en utilisant des règles basées sur l’IA pour une automatisation de bout en bout de ce qui était auparavant une tâche manuelle fastidieuse.
- Automatisation de la gestion des sinistres : la déclaration de sinistre en cas d’assurance habitation ou d’assurance automobile, par exemple, impliquait auparavant une expertise sur le terrain par les agents de la compagnie d’assurance, des déplacements chez les mécaniciens ou sur les chantiers de construction pour obtenir des estimations. Aujourd’hui, grâce à l’automatisation intelligente et à la vision par ordinateur, un propriétaire ou un automobiliste peut faire une déclaration de sinistre par photographie ou vidéo, et l’assureur peut estimer les dégâts et approuver la demande d’indemnisation en limitant l’intervention humaine aux tâches d’expertise pointues et aux étapes de validation.
- Robotisation d’applications anciennes ou virtualisées : les robots peuvent aujourd’hui facilement repérer les composants graphiques des applications web ou des applications lourdes modernes. Néanmoins, dans certains cas (e.g. virtualisation Citrix), le robot ne peut se baser que sur de l’image, et non sur les composants graphiques des applications. Dans ce cas, la vision par ordinateur permet au robot d’identifier de façon fiable les composants de ces applications (e.g. zone de saisie, case à cocher, bouton radio). Ci-dessous, un exemple de reconnaissance par un robot des divers composants graphiques d’une fenêtre sur un bureau virtuel :
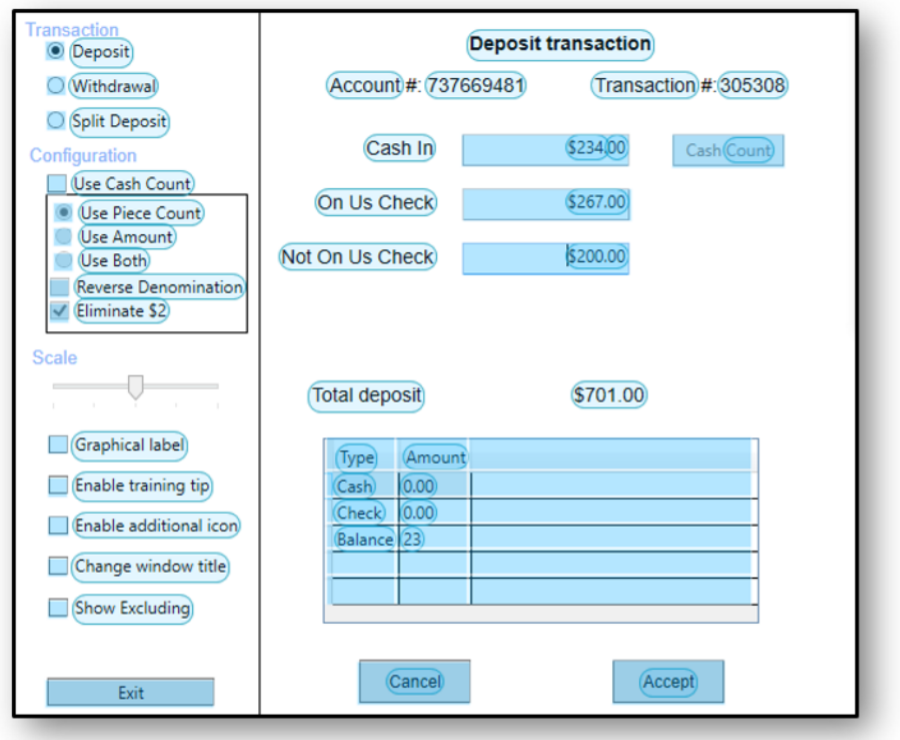
Ces quelques cas d’usage ne reflètent qu’une partie de ce qui est – et sera – possible avec l’automatisation intelligente utilisant la vision par ordinateur. Parmi les autres cas d’utilisation qui émergent déjà, nous pouvons notamment citer :
- l’inspection de sécurité des équipements ;
- les caisses automatisées des magasins ;
- les diagnostics médicaux ;
- la vidéo-surveillance ;
- la reconnaissance des empreintes digitales et biométrie.
Dans le domaine de la transformation digitale, l’intégration de la vision par ordinateur aux robots est de plus en plus courante. Cela permettra d’automatiser des tâches dont la charge cognitive est de plus en plus importante, et permettra de traiter automatiquement des processus toujours plus complexes.
A propos de StoryShaper :
StoryShaper est une start-up innovante qui accompagne ses clients dans la définition de leur stratégie digitale et le développement de solutions d’automatisation sur-mesure.
Source : StoryShaper




